Introduction to Disjoint Set Data Structure or Union-Find Algorithm
Last Updated :
16 Feb, 2023
A disjoint-set data structure is defined as a data structure that keeps track of a set of elements partitioned into a number of disjoint (non-overlapping) subsets.
A union-find algorithm is an algorithm that performs two useful operations on such a data structure:
- Find: Determine which subset a particular element is in. This can be used for determining if two elements are in the same subset.
- Union: Join two subsets into a single subset. Here first we have to check if the two subsets belong to same set. If no, then we cannot perform union.
UNION and FIND Operations for Disjoint Sets
A relation over a set of elements a1, a2,…a n can be divided into equivalent classes. The equivalent class of an element a is the subset of S that contains all the elements of S that are related to a.
Divide a set of elements into equivalent classes through the two operations
1. UNION
2. FIND
A set is divided into subsets. Each subset contains related elements. If we come to know that the two element ai and aj are related, then we can do the followings:
1. Find the subset : Si containing ai
2.Find the subset : Sj containing aj
3. If S, and Si are two independent subsets
then we create a new subset by taking union of Si and Sj
New subset = Si C ∪ P S j .
This algorithm is dynamic as during the course of the algorithm, the sets can change via the union operation.
Example:
Let us check an example to understand how the data structure is applied. For this consider the following problem statement
Problem: Given an undirected graph, the task is to check if the graph contains a cycle or not.
Examples:
Input: The following is the graph
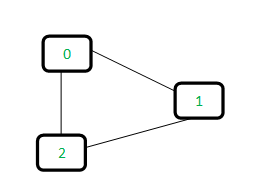
Output: Yes
Explanation: There is a cycle of vertices {0, 1, 2}.
We already have discussed an algorithm to detect cycle in directed graph. Here Union-Find Algorithm can be used to check whether an undirected graph contains cycle or not. The idea is that,
Initially create subsets containing only a single node which are the parent of itself. Now while traversing through the edges, if the two end nodes of the edge belongs to the same set then they form a cycle. Otherwise, perform union to merge the subsets together.
Note: This method assumes that the graph doesn’t contain any self-loops.
Illustration:
Follow the below illustration for a better understanding
Let us consider the following graph:
Use an array to keep track of the subsets and which nodes belong to that subset. Let the array be parent[].
Initially, all slots of parent array are initialized to hold the same values as the node.
parent[] = {0, 1, 2}. Also when the value of the node and its parent are same, that is the root of that subset of nodes.
Now process all edges one by one.
Edge 0-1:
=> Find the subsets in which vertices 0 and 1 are.
=> 0 and 1 belongs to subset 0 and 1.
=> Since they are in different subsets, take the union of them.
=> For taking the union, either make node 0 as parent of node 1 or vice-versa.
=> 1 is made parent of 0 (1 is now representative of subset {0, 1})
=> parent[] = {1, 1, 2}
Edge 1-2:
=> 1 is in subset 1 and 2 is in subset 2.
=> Since they are in different subsets, take union.
=> Make 2 as parent of 1. (2 is now representative of subset {0, 1, 2})
=> parent[] = {1, 2, 2}
Edge 0-2:
=> 0 is in subset 2 and 2 is also in subset 2.
=> Because 1 is parent of 0 and 2 is parent of 1. So 0 also belongs to subset 2
=> Hence, including this edge forms a cycle.
Therefore, the above graph contains a cycle.
Follow the below steps to implement the idea:
- Initially create a parent[] array to keep track of the subsets.
- Traverse through all the edges:
- Check to which subset each of the nodes belong to by finding the parent[] array till the node and the parent are the same.
- If the two nodes belong to the same subset then they belong to a cycle.
- Otherwise, perform union operation on those two subsets.
- If no cycle is found, return false.
Below is the implementation of the above approach.
C++
#include <bits/stdc++.h>
using namespace std;
class Edge {
public:
int src, dest;
};
class Graph {
public:
int V, E;
Edge* edge;
};
Graph* createGraph(int V, int E)
{
Graph* graph = new Graph();
graph->V = V;
graph->E = E;
graph->edge = new Edge[graph->E * sizeof(Edge)];
return graph;
}
int find(int parent[], int i)
{
if (parent[i] == i)
return i;
return find(parent, parent[i]);
}
void Union(int parent[], int x, int y) { parent[x] = y; }
int isCycle(Graph* graph)
{
int* parent = new int[graph->V];
for(int i = 0; i < graph->V; i++) {
parent[i] = i;
}
for (int i = 0; i < graph->E; ++i) {
int x = find(parent, graph->edge[i].src);
int y = find(parent, graph->edge[i].dest);
if (x == y)
return 1;
Union(parent, x, y);
}
return 0;
}
int main()
{
int V = 3, E = 3;
Graph* graph = createGraph(V, E);
graph->edge[0].src = 0;
graph->edge[0].dest = 1;
graph->edge[1].src = 1;
graph->edge[1].dest = 2;
graph->edge[2].src = 0;
graph->edge[2].dest = 2;
if (isCycle(graph))
cout << "Graph contains cycle";
else
cout << "Graph doesn't contain cycle";
return 0;
}
|
C
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
struct Edge {
int src, dest;
};
struct Graph {
int V, E;
struct Edge* edge;
};
struct Graph* createGraph(int V, int E)
{
struct Graph* graph
= (struct Graph*)malloc(sizeof(struct Graph));
graph->V = V;
graph->E = E;
graph->edge = (struct Edge*)malloc(
graph->E * sizeof(struct Edge));
return graph;
}
int find(int parent[], int i)
{
if (parent[i] == -1)
return i;
return find(parent, parent[i]);
}
void Union(int parent[], int x, int y)
{
parent[y] = x;
}
int isCycle(struct Graph* graph)
{
int* parent = (int*)malloc(graph->V);
memset(parent, -1, sizeof(graph->V));
for (int i = 0; i < graph->E; ++i) {
int x = find(parent, graph->edge[i].src);
int y = find(parent, graph->edge[i].dest);
if (x == y && (x!=-1 && y!=-1))
return 1;
Union(parent, x,y);
}
return 0;
}
int main()
{
int V = 3, E = 3;
struct Graph* graph = createGraph(V, E);
graph->edge[0].src = 0;
graph->edge[0].dest = 1;
graph->edge[1].src = 1;
graph->edge[1].dest = 2;
graph->edge[2].src = 0;
graph->edge[2].dest = 2;
if (isCycle(graph))
printf("Graph contains cycle");
else
printf("Graph doesn't contain cycle");
return 0;
}
|
Java
import java.io.*;
import java.lang.*;
import java.util.*;
public class Graph {
int V, E;
Edge edge[];
class Edge {
int src, dest;
};
Graph(int v, int e)
{
V = v;
E = e;
edge = new Edge[E];
for (int i = 0; i < e; ++i)
edge[i] = new Edge();
}
int find(int parent[], int i)
{
if (parent[i] == i)
return i;
return find(parent, parent[i]);
}
void Union(int parent[], int x, int y)
{
parent[x] = y;
}
int isCycle(Graph graph)
{
int parent[] = new int[graph.V];
for (int i = 0; i < graph.V; ++i)
parent[i] = i;
for (int i = 0; i < graph.E; ++i) {
int x = graph.find(parent, graph.edge[i].src);
int y = graph.find(parent, graph.edge[i].dest);
if (x == y)
return 1;
graph.Union(parent, x, y);
}
return 0;
}
public static void main(String[] args)
{
int V = 3, E = 3;
Graph graph = new Graph(V, E);
graph.edge[0].src = 0;
graph.edge[0].dest = 1;
graph.edge[1].src = 1;
graph.edge[1].dest = 2;
graph.edge[2].src = 0;
graph.edge[2].dest = 2;
if (graph.isCycle(graph) == 1)
System.out.println("Graph contains cycle");
else
System.out.println(
"Graph doesn't contain cycle");
}
}
|
Python3
from collections import defaultdict
class Graph:
def __init__(self, vertices):
self.V = vertices
self.graph = defaultdict(list)
def addEdge(self, u, v):
self.graph[u].append(v)
def find_parent(self, parent, i):
if parent[i] == i:
return i
if parent[i] != i:
return self.find_parent(parent, parent[i])
def union(self, parent, x, y):
parent[x] = y
def isCyclic(self):
parent = [0]*(self.V)
for i in range(self.V):
parent[i] = i
for i in self.graph:
for j in self.graph[i]:
x = self.find_parent(parent, i)
y = self.find_parent(parent, j)
if x == y:
return True
self.union(parent, x, y)
g = Graph(3)
g.addEdge(0, 1)
g.addEdge(1, 2)
g.addEdge(2, 0)
if g.isCyclic():
print("Graph contains cycle")
else:
print("Graph does not contain cycle ")
|
C#
using System;
class Graph {
public int V, E;
public Edge[] edge;
public class Edge {
public int src, dest;
};
public Graph(int v, int e)
{
V = v;
E = e;
edge = new Edge[E];
for (int i = 0; i < e; ++i)
edge[i] = new Edge();
}
int find(int[] parent, int i)
{
if (parent[i] == i)
return i;
return find(parent, parent[i]);
}
void Union(int[] parent, int x, int y)
{
parent[x] = y;
}
int isCycle(Graph graph)
{
int[] parent = new int[graph.V];
for (int i = 0; i < graph.V; ++i)
parent[i] = i;
for (int i = 0; i < graph.E; ++i) {
int x = graph.find(parent, graph.edge[i].src);
int y = graph.find(parent, graph.edge[i].dest);
if (x == y)
return 1;
graph.Union(parent, x, y);
}
return 0;
}
public static void Main(String[] args)
{
int V = 3, E = 3;
Graph graph = new Graph(V, E);
graph.edge[0].src = 0;
graph.edge[0].dest = 1;
graph.edge[1].src = 1;
graph.edge[1].dest = 2;
graph.edge[2].src = 0;
graph.edge[2].dest = 2;
if (graph.isCycle(graph) == 1)
Console.WriteLine("Graph contains cycle");
else
Console.WriteLine(
"Graph doesn't contain cycle");
}
}
|
Javascript
<script>
var V, E;
var edge;
class Edge
{
constructor()
{
this.src = 0;
this.dest = 0;
}
};
function initialize(v,e)
{
V = v;
E = e;
edge = Array.from(Array(E), () => Array());
}
function find(parent, i)
{
if (parent[i] == i)
return i;
return find(parent, parent[i]);
}
function Union(parent, x, y)
{
parent[x] = y;
}
function isCycle()
{
var parent = Array(V).fill(0);
for(var i = 0; i < V; ++i)
parent[i] = i;
for (var i = 0; i < E; ++i)
{
var x = find(parent,
edge[i].src);
var y = find(parent,
edge[i].dest);
if (x == y)
return 1;
Union(parent, x, y);
}
return 0;
}
var V = 3, E = 3;
initialize(V, E);
edge[0].src = 0;
edge[0].dest = 1;
edge[1].src = 1;
edge[1].dest = 2;
edge[2].src = 0;
edge[2].dest = 2;
if (isCycle() == 1)
document.write("Graph contains cycle");
else
document.write("Graph doesn't contain cycle");
</script>
|
Output
Graph contains cycle
Note that the implementation of union() and find() is naive and takes O(n) time in the worst case. These methods can be improved to O(logN) using Union by Rank or Height. We will soon be discussing Union by Rank in a separate post.
Auxiliary Space: O(1)
Related Articles :
Union-Find Algorithm | Set 2 (Union By Rank and Path Compression)
Disjoint Set Data Structures (Java Implementation)
Greedy Algorithms | Set 2 (Kruskal’s Minimum Spanning Tree Algorithm)
Job Sequencing Problem | Set 2 (Using Disjoint Set)
Share your thoughts in the comments
Please Login to comment...